05 ClickHouse Kafka Engine
https://clickhouse.com/docs/integrations/kafka/kafka-table-engine
To use the Kafka table engine, you should be broadly familiar with ClickHouse materialized views.
Overview
Initially, we focus on the most common use case: using the Kafka table engine to insert data into ClickHouse from Kafka.
The Kafka table engine allows ClickHouse to read from a Kafka topic directly. Whilst useful for viewing messages on a topic, the engine by design only permits one-time retrieval, i.e. when a query is issued to the table, it consumes data from the queue and increases the consumer offset before returning results to the caller. Data cannot, in effect, be re-read without resetting these offsets.
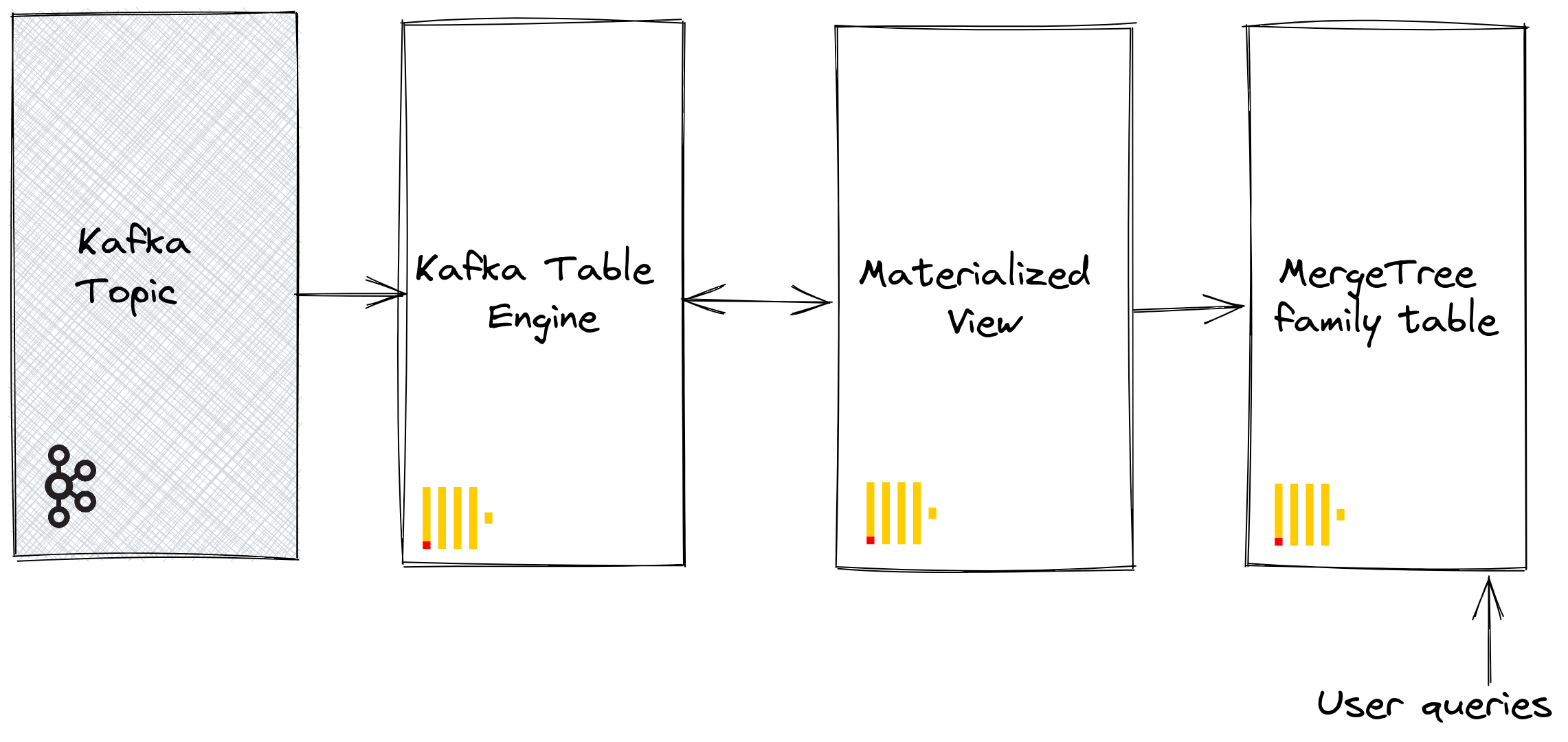
To persist this data from a read of the table engine, we need a means of capturing the data and inserting it into another table. Trigger-based materialized views natively provide this functionality. A materialized view initiates a read on the table engine, receiving batches of documents. The TO clause determines the destination of the data - typically a table of the Merge Tree family. This process is visualized below:
1. Prepare
If you have data populated on a target topic, you can adapt the following for use in your dataset. Alternatively, a sample Github dataset is provided here. This dataset is used in the examples below and uses a reduced schema and subset of the rows (specifically, we limit to Github events concerning the ClickHouse repository), compared to the full dataset available here, for brevity. This is still sufficient for most of the queries published with the dataset to work.
2. Create Database
We're also going to create a database called bitcoin to use in this tutorial:
CREATE DATABASE bitcoin;
Once you've created the database, you'll need to switch over to it:
USE bitcoin;
3. Create the destination table
Prepare your destination table. In the example below we use the reduced GitHub schema for purposes of brevity. Note that although we use a MergeTree table engine, this example could easily be adapted for any member of the MergeTree family.
CREATE TABLE blocks_fat
(
hash String,
size UInt64,
stripped_size UInt64,
weight UInt64,
number UInt64,
version UInt64,
merkle_root String,
timestamp DateTime,
timestamp_month Date,
nonce String,
bits String,
coinbase_param String,
previous_block_hash String,
difficulty Float64,
transaction_count UInt64,
transactions Array(String)
)
ENGINE = ReplacingMergeTree()
PRIMARY KEY (hash)
PARTITION BY toYYYYMM(timestamp_month)
ORDER BY hash;
CREATE TABLE transactions_fat
(
hash String,
size UInt64,
virtual_size UInt64,
version UInt64,
lock_time UInt64,
block_hash String,
block_number UInt64,
block_timestamp DateTime,
block_timestamp_month Date,
is_coinbase BOOL,
input_count UInt64,
output_count UInt64,
input_value Float64,
output_value Float64,
fee Float64,
inputs Array(Tuple(index UInt64, spent_transaction_hash String, spent_output_index UInt64, script_asm String, script_hex String, sequence UInt64, required_signatures UInt64, type String, addresses Array(String), value Float64)),
outputs Array(Tuple(index UInt64, script_asm String, script_hex String, required_signatures UInt64, type String, addresses Array(String), value Float64))
)
ENGINE = ReplacingMergeTree()
PRIMARY KEY (hash)
PARTITION BY toYYYYMM(block_timestamp_month)
ORDER BY (hash);
CREATE TABLE inputs_outputs
(
-- Inputs fields
i_transaction_hash String,
i_input_index UInt64,
i_block_hash String,
i_block_number UInt64,
i_block_timestamp DateTime,
i_spending_transaction_hash String,
i_spending_output_index UInt64,
i_script_asm String,
i_script_hex String,
i_sequence UInt64,
i_required_signatures UInt64,
i_type String,
i_addresses Array(String),
i_value Float64,
-- Outputs fields
o_transaction_hash String,
o_output_index UInt64,
o_block_hash String,
o_block_number UInt64,
o_block_timestamp DateTime,
o_spent_transaction_hash String,
o_spent_input_index UInt64,
o_spent_block_hash String,
o_spent_block_number UInt64,
o_spent_block_timestamp DateTime,
o_script_asm String,
o_script_hex String,
o_required_signatures UInt64,
o_type String,
o_addresses Array(String),
o_value Float64,
o_is_coinbase BOOL,
revision UInt64
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(i_block_timestamp)
PRIMARY KEY (i_transaction_hash, i_input_index)
ORDER BY (i_transaction_hash, i_input_index);
4. Create and populate the topic
Next, we're going to create a topic. There are several tools that we can use to do this. If we're running Kafka locally on our machine or inside a Docker container, RPK works well. We can create a topic called blocks and transactions with 3 partitions by running the following command:
kafka-topics.sh \
--create \
--topic blocks \
--bootstrap-server localhost:9092 \
--partitions 3 \
--replication-factor 1
kafka-topics.sh \
--create \
--topic transactions \
--bootstrap-server localhost:9092 \
--partitions 3 \
--replication-factor 1
kafka-topics.sh \
--create \
--topic inputs_outputs \
--bootstrap-server localhost:9092 \
--partitions 3 \
--replication-factor 1
Now we need to add these topics to consumer group. We can run a command similar to the following if we're running Kafka locally with authentication disabled:
You do not create consumer groups manually. A consumer group is automatically created the first time a consumer subscribes to a topic using a new --group (or group.id in code).
kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic blocks \
--group bitcoin-group
kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic transactions \
--group bitcoin-group
kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic inputs_outputs \
--group bitcoin-group
This creates the bitcoin-group consumer group if it doesn't already exist.
5. Create the Kafka table engine
The below example creates a table engine with the same schema as the merge tree table. This isn't strictly required, as you can have an alias or ephemeral columns in the target table. The settings are important; however - note the use of JSONEachRow as the data type for consuming JSON from a Kafka topic. The values blocks and bitcoin-group represent the name of the topic and consumer group names, respectively. The topics can actually be a list of values.
CREATE TABLE blocks_queue
(
hash String,
size UInt64,
stripped_size UInt64,
weight UInt64,
number UInt64,
version UInt64,
merkle_root String,
timestamp DateTime,
nonce String,
bits String,
coinbase_param String,
previous_block_hash String,
difficulty Float64,
transaction_count UInt64,
transactions Array(String)
)
ENGINE = Kafka('localhost:9092', 'blocks', 'bitcoin-group', 'JSONEachRow') settings kafka_thread_per_consumer = 0, kafka_num_consumers = 3;
CREATE TABLE transactions_queue
(
hash String,
size UInt64,
virtual_size UInt64,
version UInt64,
lock_time UInt64,
block_hash String,
block_number UInt64,
block_timestamp DateTime,
is_coinbase BOOL,
input_count UInt64,
output_count UInt64,
input_value Float64,
output_value Float64,
fee Float64,
inputs Array(Tuple(index UInt64, spent_transaction_hash String, spent_output_index UInt64, script_asm String, script_hex String, sequence UInt64, required_signatures UInt64, type String, addresses Array(String), value Float64)),
outputs Array(Tuple(index UInt64, script_asm String, script_hex String, required_signatures UInt64, type String, addresses Array(String), value Float64))
)
ENGINE = Kafka('localhost:9092', 'transactions', 'bitcoin-group', 'JSONEachRow')
settings kafka_thread_per_consumer = 0, kafka_num_consumers = 3, kafka_skip_broken_messages = 1;
CREATE TABLE inputs_outputs_queue
(
-- Inputs fields
i_transaction_hash String,
i_input_index UInt64,
i_block_hash String,
i_block_number UInt64,
i_block_timestamp DateTime,
i_spending_transaction_hash String,
i_spending_output_index UInt64,
i_script_asm String,
i_script_hex String,
i_sequence UInt64,
i_required_signatures UInt64,
i_type String,
i_addresses Array(String),
i_value Float64,
-- Outputs fields
o_transaction_hash String,
o_output_index UInt64,
o_block_hash String,
o_block_number UInt64,
o_block_timestamp DateTime,
o_spent_transaction_hash String,
o_spent_input_index UInt64,
o_spent_block_hash String,
o_spent_block_number UInt64,
o_spent_block_timestamp DateTime,
o_script_asm String,
o_script_hex String,
o_required_signatures UInt64,
o_type String,
o_addresses Array(String),
o_value Float64,
o_is_coinbase BOOL,
revision UInt64
)
ENGINE = Kafka('localhost:9092', 'inputs_outputs', 'bitcoin-group', 'JSONEachRow')
settings kafka_thread_per_consumer = 0, kafka_num_consumers = 3, kafka_skip_broken_messages = 1;
We discuss engine settings and performance tuning below. At this point, a simple select on the table blocks_queue should read some rows. Note that this will move the consumer offsets forward, preventing these rows from being re-read without a reset. Note the limit and required parameter stream_like_engine_allow_direct_select.
6. Create the materialized view
The materialized view will connect the two previously created tables, reading data from the Kafka table engine and inserting it into the target merge tree table. We can do a number of data transformations. We will do a simple read and insert. The use of * assumes column names are identical (case sensitive).
CREATE MATERIALIZED VIEW blocks_fat_mv TO blocks_fat
AS
SELECT
*,
toStartOfMonth(timestamp) AS timestamp_month
FROM blocks_queue;
CREATE MATERIALIZED VIEW transactions_fat_mv TO transactions_fat
AS
SELECT
*,
toStartOfMonth(block_timestamp) AS block_timestamp_month
FROM transactions_queue;
CREATE MATERIALIZED VIEW inputs_outputs_mv TO inputs_outputs
AS
SELECT
*
FROM inputs_outputs_queue;
At the point of creation, the materialized view connects to the Kafka engine and commences reading: inserting rows into the target table. This process will continue indefinitely, with subsequent message inserts into Kafka being consumed. Feel free to re-run the insertion script to insert further messages to Kafka.
7. Confirm rows have been inserted
Confirm data exists in the target table:
SELECT count() FROM blocks_fat;
SELECT count() FROM transactions_fat;
SELECT count() FROM inputs_outputs;
Common Operations
Stopping & restarting message consumption
To stop message consumption, you can detach the Kafka engine table:
DETACH TABLE blocks_queue;
This will not impact the offsets of the consumer group. To restart consumption, and continue from the previous offset, reattach the table.
ATTACH TABLE blocks_queue;
Adding Kafka Metadata
It can be useful to keep track of the metadata from the original Kafka messages after it's been ingested into ClickHouse. For example, we may want to know how much of a specific topic or partition we have consumed. For this purpose, the Kafka table engine exposes several virtual columns. These can be persisted as columns in our target table by modifying our schema and materialized view's select statement.
First, we perform the stop operation described above before adding columns to our target table.
DETACH TABLE blocks_queue;
Below we add information columns to identify the source topic and the partition from which the row originated.
ALTER TABLE blocks
ADD COLUMN topic String,
ADD COLUMN partition UInt64;
Next, we need to ensure virtual columns are mapped as required.
Virtual columns are prefixed with _.
A complete listing of virtual columns can be found here.
To update our table with the virtual columns, we'll need to drop the materialized view, re-attach the Kafka engine table, and re-create the materialized view.
DROP VIEW blocks_mv;
ATTACH TABLE blocks_queue;
CREATE MATERIALIZED VIEW blocks_mv TO github AS
SELECT *, _topic as topic, _partition as partition
FROM blocks_queue;
Newly consumed rows should have the metadata.
SELECT hash, number, topic, partition
FROM blocks
LIMIT 10;
Modify Kafka Engine Settings
We recommend dropping the Kafka engine table and recreating it with the new settings. The materialized view does not need to be modified during this process - message consumption will resume once the Kafka engine table is recreated.
Debugging Issues
Errors such as authentication issues are not reported in responses to Kafka engine DDL. For diagnosing issues, we recommend using the main ClickHouse log file clickhouse-server.err.log. Further trace logging for the underlying Kafka client library librdkafka can be enabled through configuration.
<kafka>
<debug>all</debug>
</kafka>